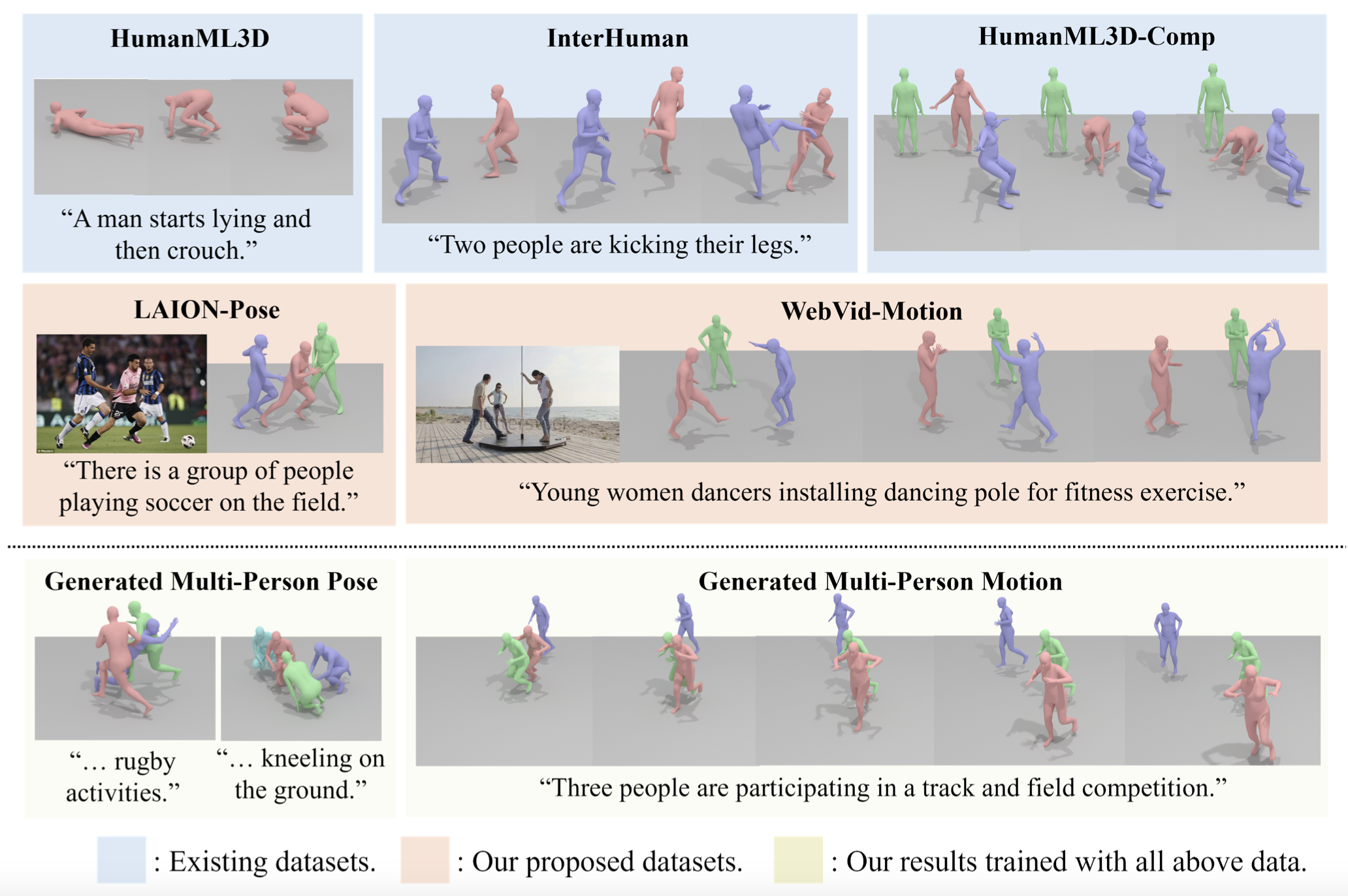
This work aims to generate natural and diverse group motions of multiple humans from textual descriptions. While single-person text-to-motion generation is extensively studied, it remains challenging to synthesize motions for more than one or two subjects from in-the-wild prompts, mainly due to the lack of available datasets. In this work, we curate human pose and motion datasets by estimating pose information from large-scale image and video datasets. Our models use a transformer-based diffusion framework that accommodates multiple datasets with any number of subjects or frames. Experiments explore both generation of multi-person static poses and generation of multi-person motion sequences. To our knowledge, our method is the first to generate multi-subject motion sequences with high diversity and fidelity from a large variety of textual prompts.
To address the data scarcity problem in multi-person domain, we introduce two datasets: LAION-Pose and WebVid-Motion, containing (image, pose, text) and (video, motion, text) tuples extracted from in-the-wild images and videos.

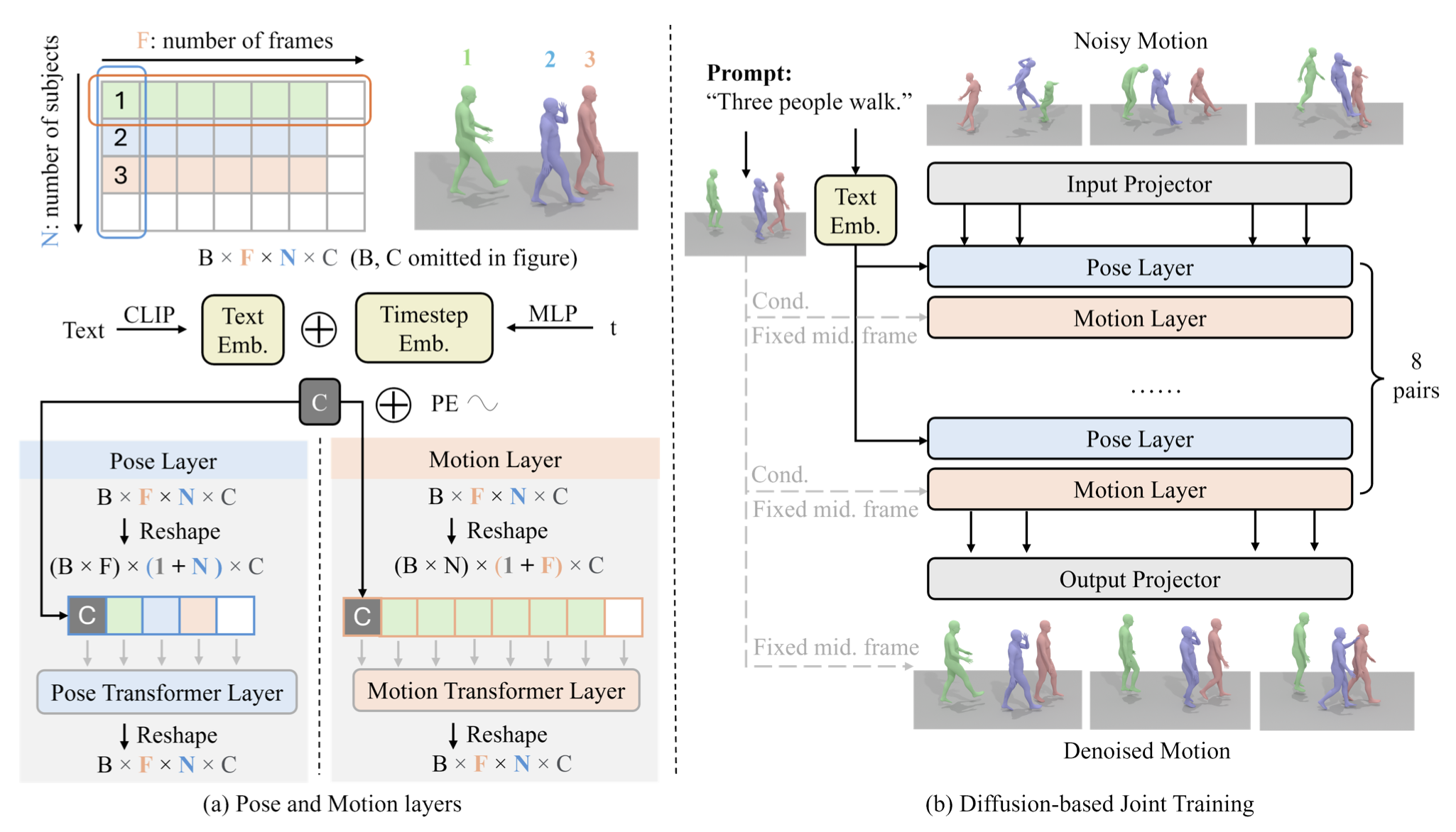
Our model is a diffusion framework consisting of interleaving pose and motion layers. At each pose/motion layer, we reshape the temporal/subject dimension into the batch dimension so that the layer focuses on generating per frame subject interac- tion and per-subject temporal movements respectively. Each layer is implemented as a transformer encoder. Diffusion time steps and text or pose conditions are encoded and summed up as a condition token concatenated to the beginning of the sequence.
@inproceedings{shan2024multiperson,
title={Towards Open Domain Text-Driven Synthesis of Multi-Person Motions},
author={Mengyi Shan, Lu Dong, Yutao Han, Yuan Yao, Tao Liu, Ifeoma Nwogu, Guo-Jun Qi, Mitch Hill},
year={2024},
booktitle={European Conference on Computer Vision (ECCV)},
}