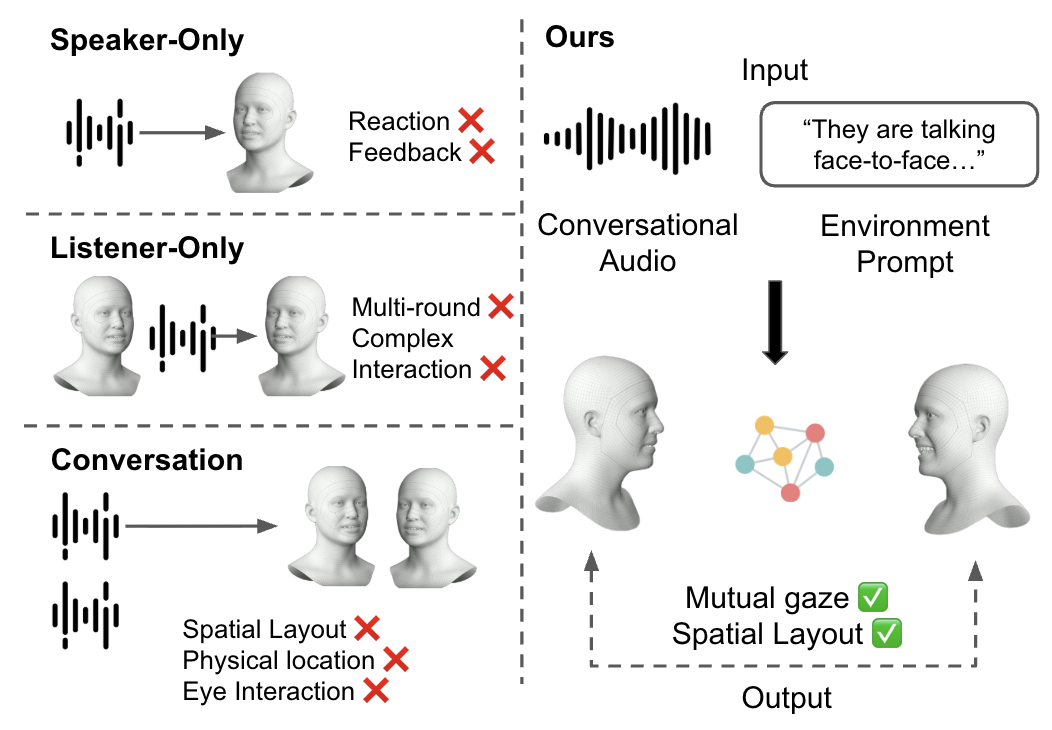
We tackle the challenging task of generating complete 3D facial animations for two
interacting, co-located participants from a mixed audio stream. While existing methods
often produce disembodied “talking heads” akin to a video conference call,
our work is the first to explicitly model the dynamic 3D spatial relationship—including
relative position, orientation, and mutual gaze—that is crucial for realistic
in-person dialogues. Our system synthesizes the full performance of both individuals,
including precise lip-sync, and uniquely allows their relative head poses to be controlled
via textual descriptions. To achieve this, we propose a dual-stream architecture where each
stream is responsible for one participant’s output. We employ speaker’s role
embeddings and inter-speaker cross-attention mechanisms designed to disentangle the mixed
audio and model the interaction. Furthermore, we introduce a novel eye gaze loss to promote
natural, mutual eye contact. To power our data-hungry approach, we introduce a novel pipeline
to curate a large-scale conversational dataset consisting of over 2 million dyadic pairs from
in-the-wild videos. Our method generates fluid, controllable, and spatially aware dyadic
animations suitable for immersive applications in VR and telepresence, significantly
outperforming existing baselines in perceived realism and interaction coherence.